Most cybersecurity conversations around AI start with familiar terrain, firewalls, access controls, encrypted data pipelines, and the usual defenses that security teams have spent years building muscle memory around. But prompt injection (tricking an AI system through malicious inputs) sits outside all of that, and that is precisely what makes it so dangerous in a world where AI systems are embedded in government services, diplomatic communications, financial infrastructure, and critical national systems.
Prompt injection is not a brute force attack. It is a semantic one, where an adversary does not break into a system so much as talk it into misbehaving, by crafting inputs that cause an AI to override its own instructions, leak sensitive data, or execute actions it was never authorised to take. The International AI Safety Report 2026 confirmed that major AI models remain vulnerable to these attacks with relatively few attempts needed to succeed, and that the success rate, while falling, is still high enough to represent a serious and active risk. OpenAI acknowledged the same year that AI browsers with agentic capabilities may always carry some level of prompt injection exposure, which is a significant admission from one of the most prominent AI developers in the world.
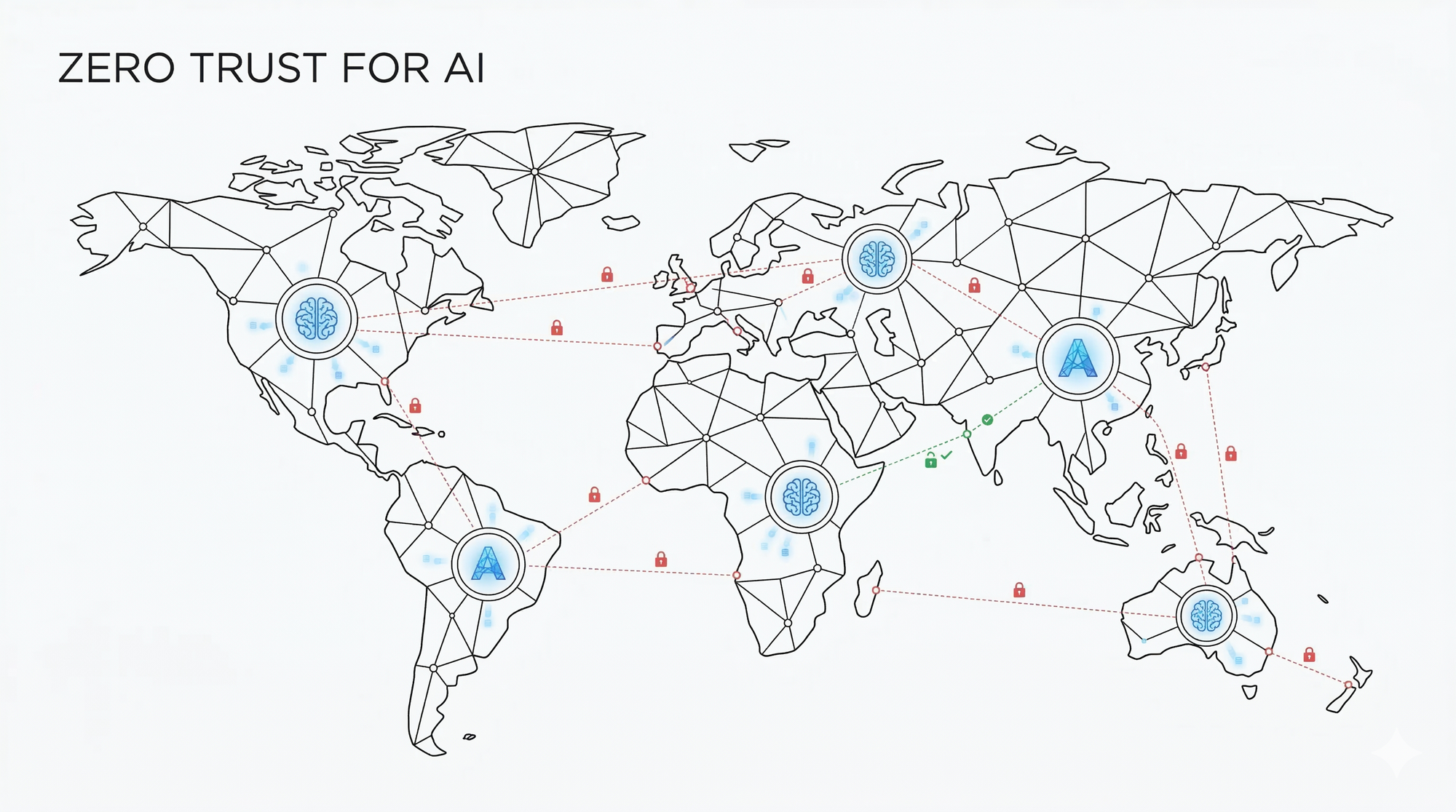
What elevates this from a product security issue to an international relations problem is who is doing the attacking and why. State-sponsored actors have already demonstrated the ability to weaponise AI systems against each other, with researchers in late 2025 documenting organised campaigns that used AI almost entirely without human interaction to breach technology companies and government agencies. The Cisco State of AI Security 2026 report went further, flagging that adversaries are now exploiting the Model Context Protocol itself, injecting malicious logic into the same infrastructure that AI agents rely on to interact with live systems and external data sources.
This is the threat landscape that traditional security testing tools were not designed to see, let alone stop. As explored in the broader context of AI-native testing, the semantic vulnerabilities embedded in AI interfaces require a fundamentally different approach to security validation, one built around continuously red-teaming AI systems and stress-testing them against adversarial inputs at scale. A penetration test that checks for SQL injection will not catch a prompt that convinces an AI assistant to summarise confidential documents and send them elsewhere.
Government agencies deploying AI in any function that touches public trust, border security, intelligence analysis, or critical infrastructure need to treat prompt injection not as a software bug but as a live geopolitical vulnerability. And the organisations building those systems carry a responsibility to test for it with the same rigour they would apply to any other weapon-grade threat.